|
I am an Applied Scientist at Amazon. I work on Amazon's suite of multimodal foundation models, with a focus on safety and alignment of generative models. We recently launched Amazon Titan (2023) and Amazon Nova (2024)
Prior to Amazon, I obtained my Master of Science in Computer Vision (MSCV) Degree at the Robotics Insitute of Carnegie Mellon University. I work with Prof. Kris Kitani on Multi-Object Tracking (MOT), and Prof. Louis-Philippe Morency on Multimodal Machine Learning. I obtained my Bachelor's Degrees from Georgia Institute of Technology with double majors in Computer Science and Industrial Engineering. I also have worked with Prof. Jim Rehg on deep learning based human gaze analysis. yongxinw [at] amazon.com / CV / Google Scholar / LinkedIn |

|
|
|
|
|
 |
Amazon Artificial General Intelligence, 2024 |
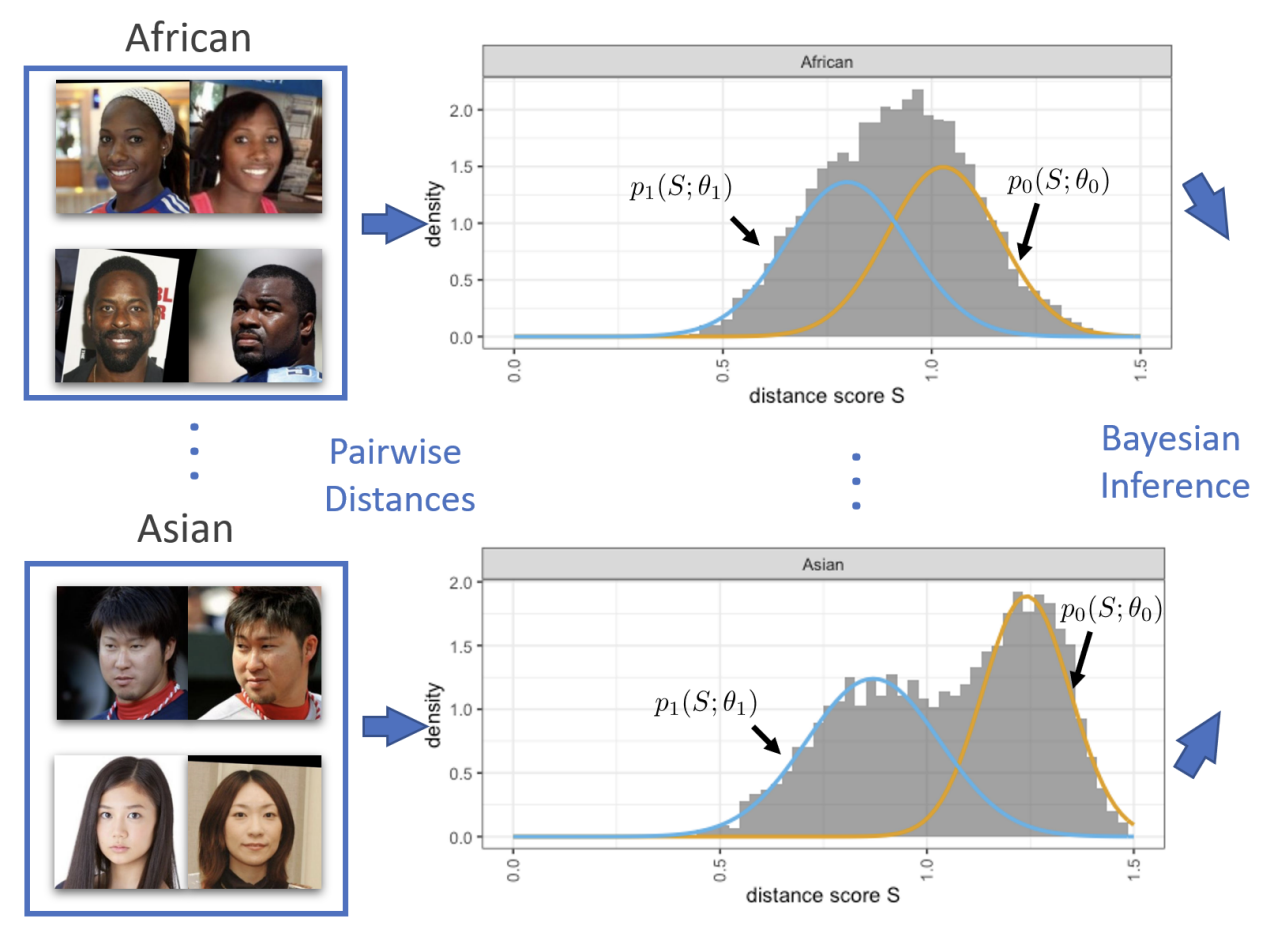 |
Alexandra Chouldechova, Siqi Deng, Yongxin Wang, Wei Xia, Pietro Perona European Conference on Computer Vision (ECCV), 2022 |
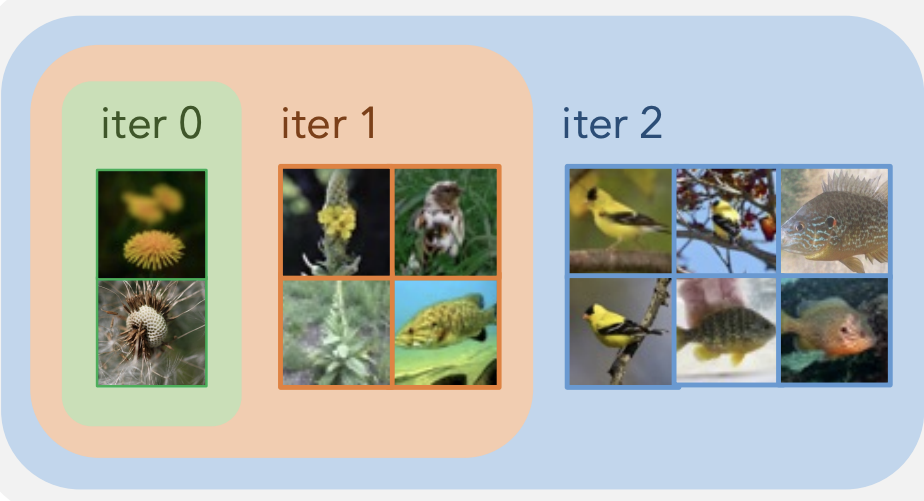 |
Tianyue Cao, Yongxin Wang, Yifan Xing, Tianjun Xiao, Tong He, Zheng Zhang, Hao Zhou, Joseph Tighe European Conference on Computer Vision (ECCV), 2022 |
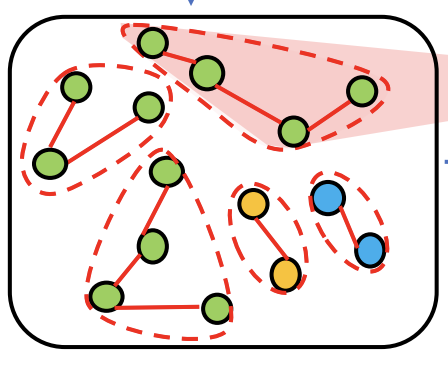 |
Yifan Xing, Tong He, Tianjun Xiao, Yongxin Wang, Yuanjun Xiong, Wei Xia, David Wipf, Zheng Zhang, Stefano Soatto International Conference on Computer Vision (ICCV), 2021 |
|
Jianing Yang*, Yongxin Wang*, Ruitao Yi, Yuying Zhu, Azaan Rehman, Amir Zadeh, Soujanya Poria, Louis-Philippe Morency Annual Conference of the North American Chapter of the Association for Computational Linguistics (NAACL-HLT), 2021 code / bibtex Modal-Temporal Graph for analysing unaligned human language sequences. (* indicates equal contribution) |

|
Yongxin Wang, Kris M. Kitani, Xinshuo Weng International Conference on Robotics and Automation (ICRA) 2021 code / website / slides / bibtex Joint detection and association using Graph Neural Networks. Named GSDT on MOTChallenge. |

|
Xinshuo Weng, Yongxin Wang, Kris M. Kitani Computer Vision and Pattern Recognition (CVPR), 2020 code / website / slides / bibtex State-of-the-art performance in 3D MOT in KITTI dataset |

|
Eunji Chong, Yongxin Wang, Nataniel Ruiz , James M. Rehg Computer Vision and Pattern Recognition (CVPR), 2020 code / dataset / bibtex Predicting where the people are looking at in videos. |

|
Eunji Chong, Nataniel Ruiz , Yongxin Wang, Yun Zhang, Agata Rozga, James M. Rehg European Conference on Computer Vision (ECCV), 2018 poster / bibtex Predicting where the people are looking at. |
|
Alex Godwin, Yongxin Wang, John T. Stasko, European Conference on Visualization (EuroVis), 2017 bibtex Visualizing social media data in a Typographic map. |
|
|
 |
Amazon AGI, Jun. 2023 - Present
Applied Scientist Launched Amazon Titan (2023) and Amazon Nova (2024) suites of foundation models, including Amazon’s large language models (LLMs), image generation models, and video generation models. Responsible for R&D to improve the performance, safety, and transparency of generative AI models. |
|
|
Amazon AutoGluon, Oct. 2022 - Jun. 2023
Applied Scientist Amazon's opensource AutoML Framekwork that allows users to train and evaluate ML models with 3 lines of code |
|
|
Amazon
Rekognition, Mar. 2020 - Oct. 2022
Applied Scientist Launched Celebrity Recognition V2 API. Launched Face Embedding Model V6 |
 |
Carnegie Mellon University,
Jan. 2019 - Mar. 2020
Research Assistant with Prof. Kris Kitani Worked on simultaneous detection and associate with Graph Neural Networks for Multi-Object Tracking |
|
|
Carnegie Mellon University,
Aug. 2019 - Mar. 2020
Research Assistant with Prof. Louis-Philippe Morency Worked on modeling multimodal temporal languange sequences with Graph Neural Networks |
|
|
Amazon
Rekognition, May. 2019 - Aug. 2019
Applied Scientist Intern with Dr. Wei Xia Worked on high-resolution face synthesis with disentangled control through facial identity and attributes |
 |
Georgia Institute of Technology, Jan. 2017 - May. 2018 Research Assistant Intern with Prof. Jim Rehg Worked on gaze target prediction in image and in video |
|
Template from here |